Text-to-video (T2V) models have shown remarkable capabilities in generating diverse videos. However, they struggle to produce user-desired stylized videos due to (i) text's inherent clumsiness in expressing specific styles and (ii) the generally degraded style fidelity. To address these challenges, we introduce StyleCrafter, a generic method that enhances pre-trained T2V models with a style control adapter, enabling video generation in any style by providing a reference image. Considering the scarcity of stylized video datasets, we propose to first train a style control adapter using style-rich image datasets, then transfer the learned stylization ability to video generation through a tailor-made finetuning paradigm. To promote content-style disentanglement, we remove style descriptions from the text prompt and extract style information solely from the reference image using a decoupling learning strategy. Additionally, we design a scale-adaptive fusion module to balance the influences of text-based content features and image-based style features, which helps generalization across various text and style combinations. styleCrafter efficiently generates high-quality stylized videos that align with the content of the texts and resemble the style of the reference images. Experiments demonstrate that our approach is more flexible and efficient than existing competitors.
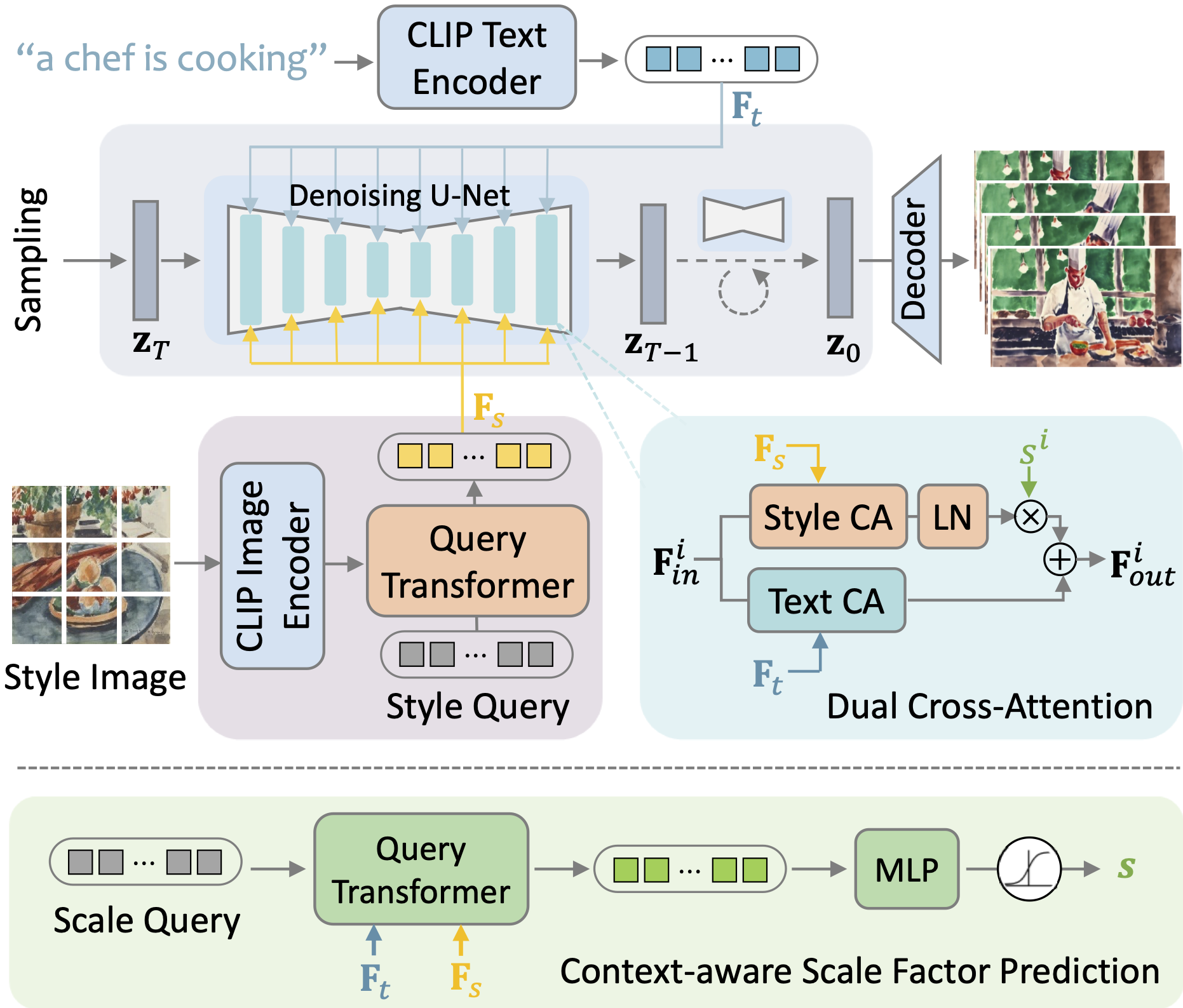
We propose a method to equip pre-trained Text-to-Video (T2V) models with a style adapter, allowing for the generation of stylized videos based on both a text prompt and a style reference image. The overview diagram is illustrated as the following figure. In this framework, the textual description dictates the video content, while the style image governs the visual style, ensuring a disentangled control over the video generation process.
Given the limited availability of stylized videos, we employ a two-stage training strategy. Initially, we utilize an image dataset abundant in artistic styles to learn reference-based style modulation. Subsequently, adaptation finetuning on a mixed dataset of style images and realistic videos is conducted to improve the temporal quality of the generated videos.
We present the comparison results of our method with other single reference style-guided Text-to-Video methods, including:
More comparison results can be found in Our Supplementary.
| Style Reference | VideoComposer([1]) | VideoCrafter*([2]) | Gen2*([4]) | Ours |
|---|---|---|---|---|
 |
> | > | > | > |
|
"A chef preparing meals in kitchen." |
||||
| Style Reference | VideoComposer([1]) | VideoCrafter*([2]) | Gen2*([4]) | Ours |
|---|---|---|---|---|
 |
> | > | > | > |
|
"A bear catching fish in a river." |
||||
| Style Reference | VideoComposer([1]) | VideoCrafter*([2]) | Gen2*([4]) | Ours |
|---|---|---|---|---|
 |
> | > | > | > |
|
"A wolf walking stealthily through the forest." |
||||
| Style Reference | VideoComposer([1]) | VideoCrafter*([2]) | Gen2*([4]) | Ours |
|---|---|---|---|---|
 |
> | > | > | > |
|
"A field of sunflowers on a sunny day." |
||||
| Style Reference | VideoComposer([1]) | VideoCrafter*([2]) | Gen2*([4]) | Ours |
|---|---|---|---|---|
 |
> | > | > | > |
|
"A rocketship heading towards the moon." |
||||
| Style Reference | VideoComposer([1]) | VideoCrafter*([2]) | Gen2*([4]) | Ours |
|---|---|---|---|---|
 |
> | > | > | > |
|
"A knight riding a horse through a field" |
||||
We present the comparison results of our method with AnimateDiff([5]) for multi-reference style-guided Text-to-Video methods.
More comparison results can be found in Our Supplementary.
| Style Reference | AnimateDiff([5]) | Ours(S-R) | Ours(M-R) |
|---|---|---|---|
 |
> | > | > |
|
"A student walking to school with backpack." |
|||
| Style Reference | AnimateDiff([5]) | Ours(S-R) | Ours(M-R) |
|---|---|---|---|
 |
> | > | > |
|
"A wolf walking stealthily through the forest." |
|||
| Style Reference | AnimateDiff([5]) | Ours(S-R) | Ours(M-R) |
|---|---|---|---|
 |
> | > | > |
|
"A student walkin to school with backpack." |
|||
[1] Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Videocomposer: Compositional video synthesis with motion controllability. arXiv preprint:2306.02018, 2023
[2] Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter1: Open diffusion models for high-quality video generation. preprint arXiv:2310.19512, 2023
[3] OpenAI. Gpt-4v(ision) system card. Technical report, 2023.
[4] Gen-2 contributors. Gen-2. Gen-2. Accessed Nov. 1, 2023 [Online] https://research.runwayml.com/gen2.
[5] Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Yu Qiao, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint:2307.04725, 2023






